Python下requests库的请求返回值为乱码/无法解码
省流版
如果requests返回的response是完全的乱码,而不是单纯的中文部分乱码,请尝试用pip安装brotli
1 | # 在终端执行 |
完整说明
问题简述
在使用python的requests对某网站发送POST请求后,发现获取到的respnse.text为乱码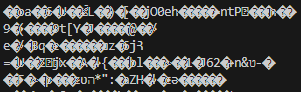
而且保存为json时也会报错
1 | Traceback (most recent call last): |
问题定位
首先想到的就是编码问题,然而像这样:response.encoding = 'utf-8'指定用utf-8解码后输出同样是乱码。
使用response.content.decode('utf-8')进行手动解码同样会报错:
1 | Traceback (most recent call last): |
与此同时,其用postman等软件发送请求后的应答则完全正常。于是认为和UTF-8的解码步骤应该无关。
此时观察返回的字节内容(response.content):\x85i\x0f\x00d\xfe_\xb7\xfa\xaf\xdf\xd9\xfb\xf5J,发现这好像也不是UTF-8对应的字节格式,是经过处理的内容。
经过排查,发现原因在于网页端的应答使用了br压缩,而python的requests库默认不支持br的解码。
解决方法也很简单,有以下两种:
- 如果网页端支持gzip等其他方式,则可以在去掉POST请求头中accept-encoding内的br。
1
2# 修改POST的Header
accept-encoding: gzip - 或者也可以为requests增加解码br压缩的能力,只需要安装brotli库:此时输出一切正常。
1
2# 在终端执行
pip install brotli
经测试,只要安装brotli库后,request就能正常解码,不需要手动在代码中引用brotli;
如果手动使用brotli.decompress(response.content).decode('utf-8')反而会报brotli.error: BrotliDecompress failed的错误